Not AI, but Abstract Statistic Systems
Recently, I held a keynote on The Al Conundrum in Photographic Art-seminar, focusing on the general understanding and discussion around generative AI. The seminar explored the reasons and ways that artificial intelligence is being used by artists today and included interesting artist talks from Hilde Honerud, Tuomo Rainio, Mikaela Steby Stenfalk, Ida Kvetny and Diana Velasco.
Moreover, the Director of the Finnish Museum of Photography, Anna-Kaisa Rastenberger, gave a wonderful commentary on my keynote, and after the talks, there was a lively discussion from the panel consisting of Anna-Kaisa Rastenberger, artists and Donald Weber, Associate Professor at Aalto University. The seminar was organised by the Association of Photographic Artists (FI) in collaboration with three Nordic photography institutions, Centrum för fotografi (SE), Fotografisk center (DK), Preus Museum (NO), and Aalto University.
Below is a transcript of that talk.

In this talk, I will map out what, at least, I think are relevant issues in the omnipresent AI discussion.
The field of AI art and research is wide and rich, but in this talk, I will focus on current technologies, such as large-language models and generative AI.
I am also thrilled to have so many artists presenting their practice today, and I think my aim is to give some kind of context to what can be some of the issues we face when we are talking or doing art about or with AI.

I think the main reason for the current hype around AI has to do with an even larger idea of automatisation. We want to automatise everything, and while this could lead to really fascinating futures and discussions of humans doing less work and -in the futuristic end- prosperity for us all.
The more realistic take is that automatisation and, therefore, AI, is so hyped because it is seen as the next way to create economic growth and more value for the stakeholders of large corporations.
Therefore, AI and automatisation are a kind of double-edged sword,
- while the theoretical possibilities and ideological ramifications are charming and attractive, the reality seems to be more and more dark. For instance, in automating arts, we are at a place where we are automating away the fun of the artistic process, and the management seems to be the only thing left for artists.
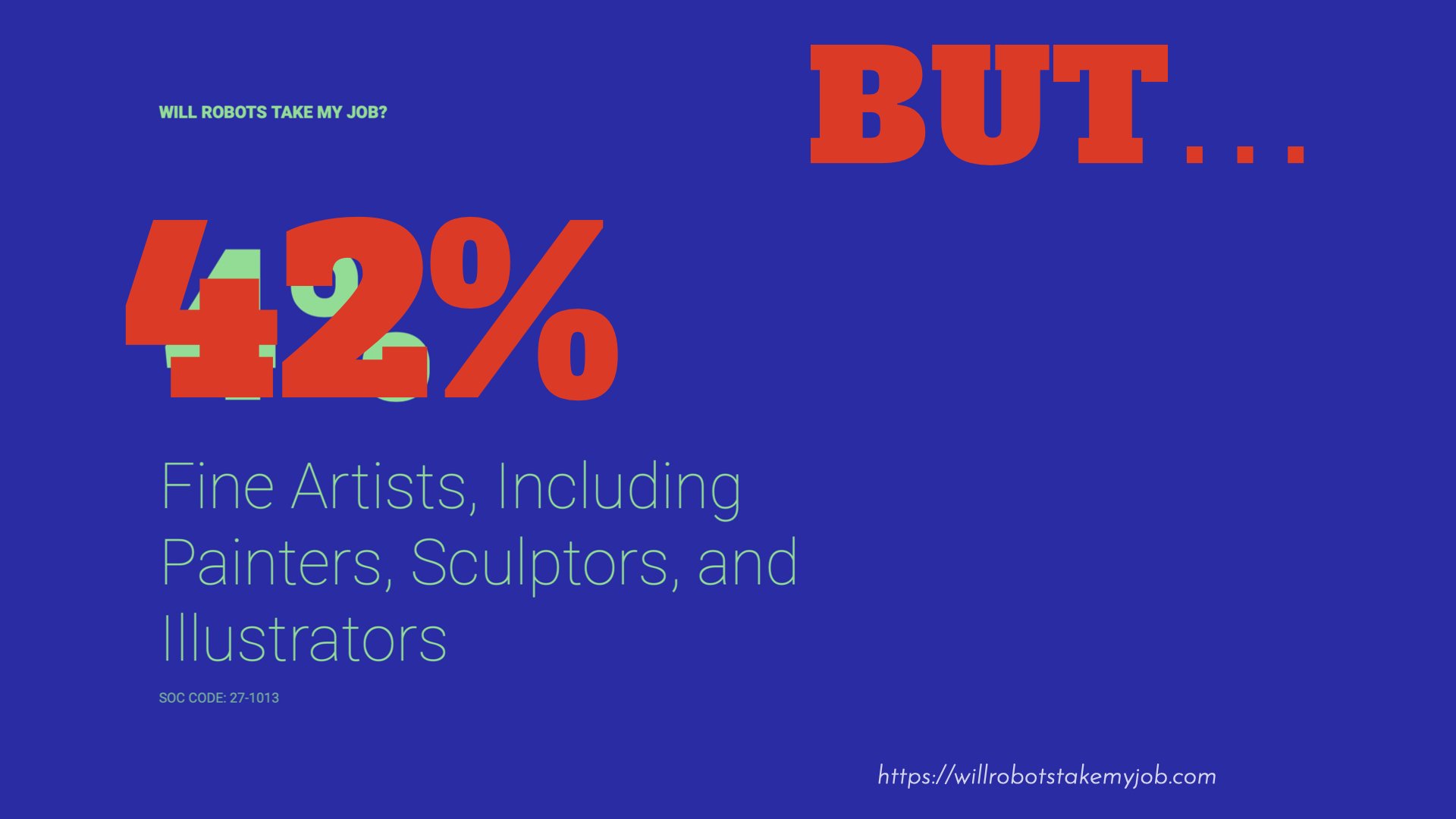
This automatisation is seen in, for instance, the danger of people losing their jobs. For a long time, it was thought that the job of artists was hard to automate, but recent advances in AI have changed that. For example, the site willrobotstakemyjob.com calculates the risk of automation for different jobs. There, the danger of artists being automated was, for a long time, only 4 per cent. But about two years ago, along with advances in generative AI, the number jumped to 42 per cent. Of course, the question is, what is it that artists do?
What parts of artist’s jobs can be automated, and what cannot?
In the end, it gets down to the questions like the importance of art and artists.
Is art just artefacts, or is it something more?

The main point of this talk is that there are a lot of misunderstandings, false hopes and fantasies around AI. Moreover, the hype often accelerates these issues. The term AI and the popularisation of it is credited to professor and researcher John McCarthy, who in 1955 held a workshop at Dartmouth on “artificial intelligence”. The research on computer intelligence is, of course, longer, and the broader idea of human-made artificial living creatures is probably as old as human culture (and what do we really know about other animals' intelligence?)
However, AI is not the only concept we could use when we talk about these technologies. During the same period, McCarthy held his lectures on artificial intelligence, the field of cybernetics was already well-established. This discipline focuses on the study of control and communication in machines.
If we had continued to use the term 'cybernetics ', derived from the Greek word 'kubernētikos' meaning 'good at steering ’, perhaps our discussions about AI today would be more grounded.
Unfortunately, this was not the case.
Together with my colleague Aaron Knochel, from Penn State University, we have been promoting that maybe we could consider abandoning the word AI when talking about generative AI; instead, we are proposing something we call a Abstract Statistic System, or a Massive Abstract Statistic system, which tries to describe what generative AI is more precisely.

But before talking about these things with some other name, I think it is important to discuss what AI, Artificial Intelligence, is. Let’s start with ARTIFICIAL

How artificial is AI actually?
Just like any technology, AI requires natural resources, physical locations and energy. AI needs to be built and maintained throughout its use, and hopefully, someone somewhere would think of recycling and end-of-line management as these things get old really fast. For instance, training the various AI models requires significant amounts of energy: energy for the calculation in the data centres, energy for running them and often fresh water to cool the data centres.
Hewlett Packard Enterprises' chief architect for AI-cloud services, Nicolas Dubé, did, according to him, a humorous calculation of how many tomatoes you can grow just by training GPT-3 one time. According to his calculations, it’s unsurprisingly a lot.
A million tomatoes.
Moreover, Kate Crawford has underlined that the material cost of AI is not only the energy and raw materials required for the data centres, but in addition, require human labour, infrastructures, logistics, histories, and classifications. The AI we use would be nothing without the massive training and data centres and the infrastructures that make such things possible. In fact, she points out that AI as we know it depends entirely on a much wider set of political and social structures.

On the software side, the code and data are not disconnected from the real world. This connection, glued together by code and algorithms, is not without faults. Algorithms create the systems, but at the same time, they create something we could call algorithm bias, which is often seen in the discriminating outcomes AI generates. The algorithms behind the models derive from data and statistics. Moreover, the algorithms are naturally made by humans, and therefore, the humans in question and their larger socio-cultural backgrounds matter.
An algorithm is always a compromise, a calculation, and an optimisation of the available data and wanted outcome. The models are thus simplifications of the complicated reality they present. And as for instance, Cathy O’Neil points out, that these processes can not see into the future, rather they codify the past. Algorithms make laws and architectures into how data is handled, as well as how prompts the end-user are handled.

Besides algorithms, AI also requires data, a lot of data. But what is data? How much do we pay attention to how information is transformed into data, and by whom? Maybe we don’t even consider that data is not the truth? But reality is that data does not represent the truth, the world or reality. It is a managed and curated collection of information.
The pictures on the slide show one of the first hard drives ever created. It is a bicycle wheel with attached magnets. The state of the magnets can then be read into the computer, and information can be stored digitally. The two other photos show an oscillogram of the read data. As you can see, the data is actually analogue; it is a waveform with values and complexity, and only after filtering it, we get something that resembles digital data.
Modern computers don’t usually have bicycle wheels anymore, but it nicely shows one material side of data and processing data.
In short, datafying information into optimised data may strip significant proportions of the information away.
It matters what gets counted because, at the same time, we choose what is right and wrong, what is needed and what is not needed, what is stored and what is forgotten.

Even though we have a lot of data, we don’t have enough data. Nigerian American artist Mimi Ọnụọha has raised these issues in her work The Library of Missing Datasets. Her work consists of datasets that we might think exist but do not exist. These datasets include things like:
Sales and prices in the art world (and relationships between artists and gallerists)
People excluded from public housing because of criminal records
Trans people killed or injured in instances of hate crime (note: existing records are notably unreliable or incomplete)
Poverty and employment statistics that include people who are behind bars
Muslim mosques/communities surveilled by the FBI/CIA
Mobility for older adults with physical disabilities or cognitive impairments
LGBT older adults discriminated against in housing
Undocumented immigrants currently incarcerated and/or underpaid
Undocumented immigrants for whom prosecutorial discretion has been used to justify release or general punishment
Measurements for global web users that take into account shared devices and VPNs
Firm statistics on how often police arrest women for making false rape reports
Master database that details if/which Americans are registered to vote in multiple states
Total number of local and state police departments using stingray phone trackers (IMSI-catchers)
How much Spotify pays each of its artists per play of song

The selection of what to include as data does not come without problems. For one, there is a problem with the cleanliness of data. Meaning that we need to treat, wash and prepare the data to get it ”usable”. Often, this also means we whiten the data, as data science is mostly made in the white global north.
Another example of the issue is what D’Ignazio and Klein call Big Dick Data in their book Data Feminism. Big Dig data projects prefer speed and size and boast with its capabilities. One example of a “Big Dick Data” project is Palantir Gotham, which Victoria Stahls writes about, and I quote
”which integrates and transforms massive volumes of data and presents them into a single coherent data asset where the user can make faster and ideally more confident decisions. Palantir Gotham was contracted by Europol, the EU’s law enforcement agency, to compile millions of items of information. This data ranged from criminal records, witness statements, and police reports. Palantir Gotham was contracted by Europol to crunch this wide range of data relating to crime into actionable intelligence. But what does actionable intelligence actually mean? It can mean different things to many different parties involved.” End quote.
Palantir Gotham gathers a lot of data to be used in law enforcement. However, it can easily also overemphasise certain geographical locations and people of colour and, for instance, leave certain kinds of crime, like white-collar crime, invisible.
In short, the artificial in AI is a wide variety of diverse things, all very connected to very real things.

From artificial, let’s jump to intelligence in AI

One of the popular ways to describe AI is to categorise it by its intelligence or just capabilities.
The weak, or narrow AI, is the AI and the only AI we have right now, and arguably in the foreseeable future. Narrow AI means AI that is not conscious, and that has narrow, restricted capabilities. For instance, we can ask chatGPT a lot of things, but if I ask it to make me coffee, it cannot do it. However, the capabilities of narrow AI are significant and often surpasses humans equivalent skills. Narrow AI runs most of the stock exchange, corrects our language and does a massive amount of other tasks in our everyday lives.
General AGI, or often Artificial General Intelligence, AGI, refers to AI that would be capale of solving any problem. Meaning it could answer questions and make me coffee. It’s capabilities would then be similar to us humans, or even surpass them. Super AI follows from AGI. Thinking is that when we have general artificial intelligence, we can ask it to make a better version of itself and do it faster. Eventually, or so the thinking goes, the development cycles become so frequent and fast that a sort of singularity, super AI, is born. This can take the form of an intelligence we can then load ourselves (minds, brains) into and live forever, or something that destroys us, depending on who you ask. It is the AI of popular culture, Skynet and Matrix.
The problem with such a three-fold characterisation of AI is that it very quickly becomes a timeline, something we strive forward to, even as the narrow AI we are dealing with now is nothing like the other two intelligences.
This mixing of fantasy and reality is something that is common in both general, expert and academic views on AI as well as in the media’s expression of AI. As an example, in an article I wrote with Pekka Mertala, we concluded that many AI researchers have, at the same time, quite sober and realistic picture of the type of AI we have now, but, however, many same time have unrealistic fantasies of the trajectory forward. i.e. ideas about Super AI.
This can be seen, for instance, in OPEN AI’s recent media catastrophe with Scarlett Johannson and the copying of her voice without permission. There seems to be a strong urge to make AI into something depicted in movies.

Leaving the fantasyland of AI as Matrix, Skynet or as Scarlett Johansson’s voice aside, the narrow AI, in short, relies a great deal on the mathematical foundation provided by statistics, enabling AI to make predictions, identify patterns, and make decisions based on data. This is, of course, understandable if we think of what, for instance, LLM’s or generative AI does; It relies on data and statistics.
However, the field of statistics, however exciting it might be, is not often highlighted in the portrayals of AI in media. Instead, media is often filled with words that convey something magical, living, conscious, or miraculous.

One of the problems with identifying intelligence only from a mathematic, statistical standpoint is that all the other intelligences get moved to the side. As Nancy Katherine Hayles noted already in her 1999 book How We Became Posthuman, thinking of intelligence as the sole property of symbols, of digital data, leaves embodiment and other intelligence outside the digital realm.
Hayles is not the only, or the first, one to call attention to the concept of intelligence. Howard Gardner has famously proposed of altogether eight bits of intelligence that can be differenced from each other. These include visual-spatial, musical, linguistic and, for instance, logico-mathematical intelligence. Gardners ideas have been very popular, for instance, in education and education research. And for instance, Robert Stenberg has proposed that intelligence can be divided into three parts: Analytical, Creative, and Practical intelligence, each depicting how individuals deal with changes and challenges.

The discussion of intelligence also touches closely on the discussion of art. What is the meaning of art? What is art? What are the relations between art, intelligence and statistics?
Scott Kaufman has, for instance, highlighted how artists have intelligence in leaving prior preconceptions behind, dare I say, leaving the statistical models behind and finding meaning in the here and now. A bit similarly, Alva Noë has argued that art is something that does not fit into explanation, that art is how we move our society and culture forward. Art is a strange tool that disrupts our habitual, organised lives. Posthuman and new materialist thinkers even tie art and intelligence into an entangled mess, drawing attention away from human-centred views and more into the agencies of all things, not only humans.

When we consider intelligence in AI, we have to have an understanding of what intelligence we are talking about. And still, we can ask that behind the model and statistics, is there a meaning or, as Emily Bender puts it, are we only dealing with a stochastic parrot, meaning a model that can generate plausible synthetic text without having any understanding of it.
The AI models do not read, write or understand the data like humans. They don’t treat the words and images like humans. Instead they fold them into multidimensional models and calculate the probabilities of everything, of every letter combination or pixel combination. Words and images get broken into irregular pieces in what Marco Dommarumma calls a Frankenstenian system.
Models created by AI do not have the same comprehension of the data we feed into them. Moreover, the data is at least twice abstracted from the collected information. First, we have the collected data and the representation of it. From there, AI models create their own representation - a model of it.
This is why we call the statistic models abstract. The AI model and how it works is abstract for us humans.

AI-generated image is thus interestingly representing our collective, collected, datafied world and, at the same time, abstract, uncomprehensible to us. Alexander Galloway has, in his book Uncomputable, argued that even a normal computer-generated image is nearer to an architectural model than a photograph or painting.
Galloway's concept is that a computer-generated image is not just a visual representation but an algorithm that encapsulates the entire problem space of the possible image. Computer images do not have perspective-like vanishing points; rather, it is a model of something and has all the points of the image. Therefore, argues Galloway, a computer-generated image is more like an architectural model than a normal image.
The model, of course, is not the reality but a curated collection based, on some part, on reality.
In turn, AI images are even more abstract. AI images represent the abstracted model of the human-made model. In short, AI images are the images of the model itself.

The images AI creates are the optimised statistic snapshots into the model. As such the models favour the average, the median. For the model, the best image is what better equals the complex statistical problems.
As Cathy O’Neil argued, algorithms codify the past; generative AI images follow a similar trajectory. In doing so, AI is conservative and, as Roland Meyer puts it, even nostalgic.

The statistical model is thus directly connected to the biases in data. The current datasets include, for instance, a lot of image material from eugenics studies from the 19th and early 20th centuries. The statistics models resurface, for instance, the thinking that by looking at people, we can see whether they are criminals or not. Or consider the implications of an AI startup promising to provide corporations with information about a job applicant's sexual orientation. This is a clear example of the potential misuse of AI and synthetic data.

The popular use of the generated images has also started affecting the broader digital world. For instance, for a while, Google's image search showed this picture as a top result for the search for the Tiananmen Square tank man. The problem is that the image is not real; it is an AI-generated selfie.
Such images have started polluting the internet. Moreover, some studies have shown how AI-generated images actually poison digital architecture because AI-generated images differ from ”real” digital images, and the models don’t, therefore, understand them, leading to odd behaviour of the model.
In an upcoming text, I delve into the contrast between AI images and Jean Baudrillard's concept of simulacra and hyperreal. Baudrillard's hyperreal refers to a reality without origin. In a similar vein, AI-generated images create a 'hyper hyperreal ', a reality that not only influences our thoughts and culture but also permeates the technological layers of our digitally-based society.

To conclude, I want to come back to the Massive Abstract Statistic System, proposing that maybe we should stop implying that AI creates or generates something. And rather see it as a statistics machine that spits out its own statistics truths?

One might ask that
Who cares?
What’s in a name?
But the idea is not to play down the importance of generative AI. Rather than talk about it in more precise terms. It matters how we discuss these technologies because how we talk about these technologies opens or closes the landscape of possible discussion.
And it matters for the future path we take with AI. It also matters because the words we use and repeat create the layers we then think further from.
As a parting thought, I'd like to introduce four perspectives on AI that illustrate the concept of MASS: massive abstract statistical systems.

The first example is the idea of UMWELT.
The word Umwelt originates from the early twentieth-century German biologist Jakob von Uexküll, And can be literally translated as 'environment' or 'surroundings' but, being a German word, it means a lot more than that (and a presentation without a German word would be no presentation at all).
Umwelt of computers can be, for instance, understood as the opposite to a computer user, be it an artist, researcher or a scientist’s comprehension of the computer, which Uexküll calls Umgebung. So Umwelt focuses on the computers’ environments, to the way computers recognise and can act in their environment or surroundings.
British artist and author James Bridle has used the concept of umwelt when thinking about computer based intelligences. He wants to open computer intelligence to appreciate another kinds of intelligences, which we have had for a long downplayed, such as intelligence around other species and even plants and trees.
From that kind of position, computer intelligence becomes not only a statistical question of efficiency and cost savings but becoming with something, appreciating the computers as they are, not magical entities, but technological tools tied into massive human and non-human assemblage. I see umwelt as a word that could bring us closer to the technologies available today and to a position that could be more fruitful.
Instead of thinking about artificial intelligence or human-like digital behaviours, we could try to abandon our human-centred position and think about what kind of environments computers are situated in.

Another idea is exemplified by the Indigenous protocol and artificial intelligence working group that tries to think about how Indigenous epistemologies can contribute to the discussion around AI. This project shows that thinking of AI as a massive statistic machine may result in us thinking of alternative futures for AI.

Another similar project is the Intersectional AI Toolkit, which gathers ideas, ethics, and tactics for more ethical, equitable tech. It shows how established queer, antiracist, antiableist, neurodiverse, feminist communities can contribute a needed perspectives to reshape digital systems.

Lastly, I want to mention all kinds of DIY materialist computational approaches where artists engage with the current technologies from their point of view and their terms. This is a loose set of a lot of different approaches, but common is that, in some way, they have an attitude toward the technologies that could be described as anarchist and critical.
Well, I will leave it to that. There are many other examples of how we can rethink AI or strip away AI of its magical layers.
Important is that we critically asses what is the AI we are dealing with. What do we think about it, and what are our hopes with AI?

